Jailbreaking LLMs Without Gradients or Priors: Effective Transferable Attacks via Random Local Search
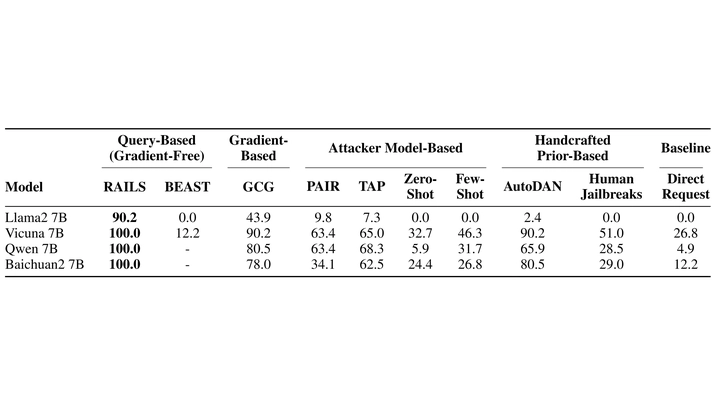 Comparison of RAILS with baselines
Comparison of RAILS with baselinesAbstract
Large Language Models (LLMs) remain vulnerable to adversarial jailbreaks, yet existing attacks rely on handcrafted priors or require white-box access for gradient propagation. We show that token-level iterative optimization can succeed without gradients and introduce RAILS (RAndom Iterative Local Search), a simple yet effective method using only model logits with a query budget comparable to gradient-based approaches. To improve attack success rates (ASRs), we incorporate a novel auto-regressive loss and history buffer-based candidate selection for few-shot attacks, achieving near 100% ASRs on robust open-source models. By eliminating token-level gradients, RAILS enables cross-tokenizer attacks. Notably, attacking ensembles of diverse models significantly enhances adversarial transferability, as demonstrated on closed-source systems such as GPT-3.5, GPT-4, and Gemini Pro. These findings demonstrate that handcrafted priors and gradient access are not necessary for successful adversarial jailbreaks, highlighting fundamental vulnerabilities in current LLM alignment.
This publication is under review. The code and the details are coming soon.